








AI-Assisted Plain Language Translation in Health Communication: Opportunities and Challenges for Editorial Workflows
Authors: Dennis Ballwieser *, Julian Hörner*, Janina Kröger – Wort & Bild Verlag, Baierbrunn, Germany
Silvana Deilen, Sergio Hernández Garrido, Ekaterina Lapshinova-Koltunski, Christiane Maaß – University of Hildesheim, Germany
*presenting author
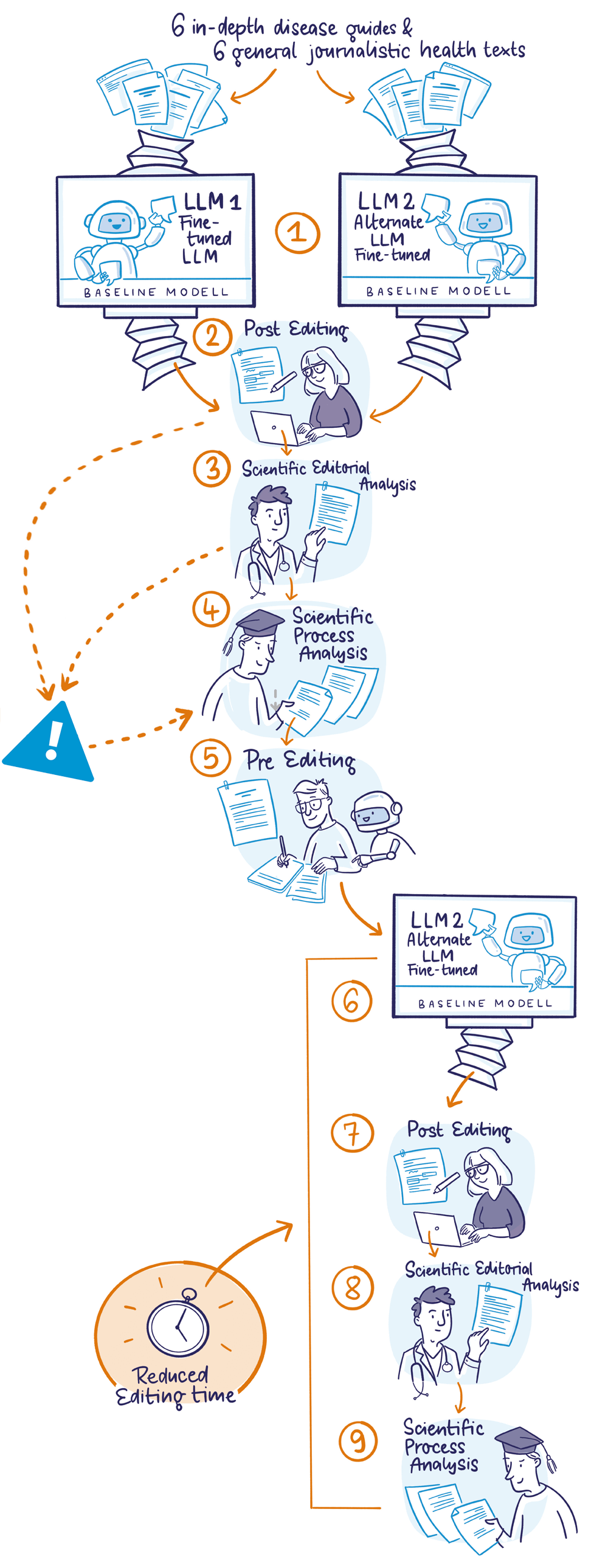
See: Model Training & AI System Setup
Post-Editing: (Professional editing of AI output) A human editor rigorously revises the AI-translated text, applying in-house Plain Language guidelines (e.g. simple vocabulary, short sentences) and correcting any inaccuracies. The editor ensures the text is clear and reader-friendly.
Scientific Editorial Analysis: (Domain expert check) A medical expert or scientific editor reviews the post-edited text for medical and factual accuracy. Any incorrect or oversimplified medical content is flagged and revised in consultation with the editor. Only after this expert feedback is integrated is the Plain Language article approved for publication.
See: Error Analysis & Challenges
Scientific Process Analysis: The error analysis revealed that one model (“Model 2”) clearly outperformed the other (“Model 1”) in terms of both speed and output quality.
It also became clear that the longer and structurally more complex the source text, the longer the post-editing process takes.
Pre-Editing: Long and complex texts are adapted and shortened into a predefined macro structure using Mistral AI. This process ensures the text level is adapted to the requirements of Plain Language texts before translation. The editorial team then reviews the AI-generated template for completeness and correctness, identifying any hallucinations. This process has effectively reduced structural issues in AI translations and minimized post-editing time.
Workflow Implementation: The proof-of-concept results were used to develop and implement an editorial workflow for AI-supported translation of medical guides into Plain Language.
Reduced Editing time: The Apotheken Umschau’s editorial team reduced translation time from days to about 4–5 hours per article by adopting this AI-assisted workflow, saving up to two-thirds of the time compared to manual translation with external service providers.
Background
- The Need: Health information is often complex. Medical terminology and implied knowledge makes it difficult for non-experts to understand[1][2]. Plain Language (easy-to-understand) texts improve comprehensibility for non-experts, especially vulnerable groups.
- AI for Simplification: Large Language Models (LLMs) offer new opportunities to simplify complex texts within the same language (intralingual translation). However, integrating AI tools into editorial workflows introduces new challenges, such as the risk of errors or oversimplification. Accuracy and readability remain critical, especially in medical communication.
- Challenge: Integrating AI into editorial workflows brings forth new challenges. AI-generated translations may include errors, “hallucinations,” or oversimplifications that editors need to correct. Ensuring accuracy and readability in medical content remains a critical factor that continues to pose significant challenges.
- Proof-of-Concept: As part of the KI-GesKom project (Research Centre for Easy Language at University of Hildesheim with Apotheken Umschau from Wort & Bild Verlag and SUMM AI), we conducted a proof-of-concept in a real editorial setting. We implemented an AI-assisted workflow for translating German health texts into Plain Language and evaluated its efficiency (time saved) and quality (error analysis).[3]
Preliminary Work: Model Training & AI System Setup
To enable the above workflow, we leveraged the SUMM AI machine translation system – one of the first tools for intralingual translation into Plain German and Easy German. In collaboration with the SUMM AI team, we developed and evaluated three versions of their model on our health content:[4]
- Baseline Model: An existing beta model for Plain German provided by SUMM AI served as our baseline. This is a large language model (LLM) that had been pre-trained and fine-tuned on the provider’s in-house data and some rule-based simplification strategies. Essentially, it’s the original system before exposure to our specific dataset.
- Model 1 – Fine-tuned LLM: Our team supplied SUMM AI with a corpus of 200 parallel texts (standard German health articles and their human-crafted Plain German translations from Apotheken Umschau); from these, 170 texts were used as training data to fine-tune the model. Model 1 uses the same underlying LLM as the baseline, but enriched with this domain-specific Plain Language data. The fine-tuning process adapted the model to the style and vocabulary of Apotheken Umschau’s plain articles, following guidelines from the Research Centre for Easy Language for consistency.
- Model 2 – Alternate LLM Fine-tuned: Model 2 was created in the next iteration, using the same 170-text training corpus but applied to a different underlying LLM. This allowed us to test another AI architecture’s performance on the task. By training a second model on the identical data, we could compare whether a different base language model would handle Plain Language translation better.
- Comparison of Model 1 and Model 2: Both Model 1 and Model 2 were then used to generate Plain German versions of a test set of 30 new articles (not seen during training), enabling a head-to-head comparison with each other, the baseline, and the human-written plain texts.
(Technical note: All models focus on German-only translation. The training data – 170 parallel texts – came from Apotheken Umschau’s online archive of Plain Language articles, which ensured the AI learned from high-quality, medically vetted translations.)
Error Analysis & Challenges
- Structural Edits: Text structure issues were the largest source of editor effort. Model 1 often produced poorly structured outputs – e.g. overly long lists or paragraphs and irrelevant details – requiring the editor to reorder or trim the content. For in-depth disease guides testers logged ~406 instances of structural interventions for Model 1 (up to 4 hours of work on structure alone). Model 2’s outputs were better organized (≈330 structural fixes, up to 3 h 45), but still demanded significant restructuring. This structural editing includes breaking up complex information into simpler segments, removing redundancies, and ensuring a logical flow in the Plain Language version.
- Table time tracking condensed version for model 1 and model 2:
| Model 1 | Model 2 | |
| post-editing (average) | 2 h 56 | 1h 32 |
| post-editing in-depth disease guides (average) | 3 h 08 | 1 h 51 |
| post-editing general health guides (average) | 2 h 45 | 1 h 12 |
| scientific review (average) | 0 h 34 | 0 h 21 |
- Language Complexity: Both models sometimes failed to simplify language sufficiently. Model 1 outputs contained many complex sentences or jargon that had to be simplified – around 110 minor language errors (grammar, punctuation) and 55 more serious complexity issues were noted in Model 1 translations. Model 2 performed better (≈65 minor and 12 complex language issues), yet editors still had to rephrase for clarity. For example, sentences that were too long or abstract were rewritten into shorter, concrete sentences. This shows that AI may grasp vocabulary but not always the level of simplicity needed for Plain Language, so editors must revise phrasing and syntax.
- Content Accuracy & “Hallucinations”: A critical challenge was accuracy. The AI sometimes introduced incorrect or misleading information while simplifying (a form of hallucination). For instance, in one medical guide, Model 1’s translation added a bullet point “Tumor im Bauch” (“tumor in the belly”) as a cause of night sweats – an oversimplification of Insulinom (insulinoma) that distorted the meaning. It also wrongly implied the pancreas alone causes hypoglycemia in diabetes, which the medical reviewer flagged as false. Such errors could mislead readers if not corrected. In our workflow, the scientific review caught these issues, and the editors removed or corrected the misinformation.
Key Findings & Conclusion
- Two LLMs Tested: We evaluated two different LLM models via the Summ AI tool on 12 German health texts (including in-depth disease guides and shorter health articles). All AI translations underwent the full post-editing and review process. Result: One model (“Model 2”) clearly outperformed the other (“Model 1”) in both speed and output quality.
- Need for Domain Expertise: Many errors were subtle and required domain knowledge to identify. In Model 1 outputs, editors themselves caught ~50 content errors (medical inaccuracies or misleading simplifications) during post-editing, and ~10 additional issues needed consultation with the medical expert. Model 2 had fewer content errors (~20 caught by editors, ~11 needing expert input), but still some critical mistakes. This underlines that AI lacks true understanding of medical content – it may produce grammatically correct text that seems plausible but isn't accurate. Thus, experienced health communicators and clinicians must review AI translations to ensure factual correctness.
- Medical vs General Content: Medical information texts required considerably more post-editing time than general journalistic health texts, for both models. For complex medical guides, Model 1 workflows averaged nearly 4 hours (3 h 59 min) and Model 2 about 2.5 hours (2 h 21 min). In contrast, simpler health articles took ~1.5 hours (1 h 24 min) (Model 2) vs ~3 hours (3 h 2 min) (Model 1). This highlights that specialized medical content is more challenging and time-consuming to edit, even with AI support.
- Time Savings: The better AI model significantly reduced editing time. On average, using Model 2 the entire post-editing process (including expert review) took 1 hour and 53 minutes per text, compared to 3 hours and 30 minutes with Model 1. In other words, Model 2 saved roughly 1.5 hours of editing time per document versus Model 1.
- Role of AI: Incorporating AI into the editorial process can significantly speed up Plain Language translation – our results showed that up to two-thirds of the time could be saved compared to manual translation with external service providers. The Apotheken Umschau editorial team was able to cut translation time from days to about 4–5 hours per article by adopting this AI-assisted workflow. However, AI is a tool, not a replacement for translators: the workflow’s success hinges on skilled human post-editors and reviewers. Our study confirms that professional post-editing remains indispensable for high-quality output. As the project’s findings echo, “AI accelerates the work but does not replace expertise.”
- Post-Editing Remains Essential: Neither model produced ready-to-publish output without substantial human editing. All AI-generated texts required extensive post-editing to fix errors and ensure adherence to Plain Language standards. In every case, editors had to adjust wording and verify facts, underscoring that the “human in the loop” is crucial for quality control. (Even the better AI model’s output was far from perfect without human refinement.)
Outlook
- Workflow Implementation: The proven efficiency gain has led to real-world adoption. The developed AI-assisted workflow has been implemented at a major German health publisher, integrating seamlessly into editorial operations. Editors now routinely use AI drafts as a starting point, then apply rigorous post-editing and expert review. This change not only saves time but also allows the team to handle more content and update information faster, benefiting readers who need accessible health information.
- AI Workflow Expansion: We are exploring extending this workflow to other text types and domains. Ongoing challenges include training AI models to reduce hallucinations and better handle domain-specific terminology. Multidisciplinary collaboration is key – AI for science communication works best when technologists, linguists, and domain experts co-create solutions. Ultimately, our work shows that a carefully designed human-AI workflow can make health information more accessible, but maintaining trust and accuracy requires keeping experts in the loop.
Acknowledgments
Our Study is part of the project KI-GesKom (Research Centre for Easy Language at Univ. Hildesheim with Apotheken Umschau from Wort & Bild Verlag and SUMM AI) The project KI-GesKom runs from May 2024 to July 2025 and is supported by Volkswagen Stiftung and the Ministry of Science and Culture Lower Saxony (MWK) as part of the “Zukunftsdiskurse 2023” funding programme.
References
[1] Kröger, Janina; Christiane Maaß (2024): “Mangelnde Verständlichkeit durch Fachsprache in Gesundheitsinformationen zu chronischen Erkrankungen – eine qualitative Korpusanalyse.” Prävention und Gesundheitsförderung 19: 497–503 – https://doi.org/10.1007/s11553-024-01124-0
[2] Ahrens, Sarah (in print). Patientinnenaufklärung beim Frauenarzt. Welche Eigenschaften müssen Einfache-Sprache-Texte haben, um für Frauen mit Deutsch als Zweitsprache verständlich und anwendbar zu sein? Berlin: Frank & Timme
[3] Kröger, Janina; Silvana Deilen; Julian Hörner; Ekaterina Lapshinova-Koltunski; Christiane Maaß (accepted for publication): „Proof of Concept. Entwicklung eines redaktionellen Workflows für die KI-gestützte Übersetzung von Gesundheitsinformationen in Einfache Sprache“ TransKom. Zeitschrift für Translationswissenschaft und Fachkommunikation
[4] Deilen, Silvana; Ekaterina Lapshinova-Koltunski, Sergio Hernández Garrido, Julian Hörner, Christiane Maaß, Vanessa Theel, Sophie Ziemer (2024): “Evaluation of intralingual machine translation for health communication.” European Association for Machine Translation Confe- rences/Workshops, 469–479 – https://aclanthology.org/2024.eamt-1.39.pdf (25.03.2025)
More on the KI-GesKom Project & Publications (German): https://www.uni-hildesheim.de/leichtesprache/forschung-und-projekte/projekte/ki-geskom/
See Our Plain Language Health Content Online (German): https://www.apotheken-umschau.de/einfache-sprache/